推しの声が好きすぎてフーリエ変換してみた話
涼花萌ちゃんの「声」が,かわいい.
突然ですが,涼花萌ちゃんの声ってとても可愛いし聞いてるとすごく癒されますよね.そこで,なぜ我々は萌ちゃんの声に惹かれるのかを知るべく,その声の特徴の解析を試みたので,その記録をここに書き残しておこうと思います.
なお,私は現在理系の大学院生なのですが,私の専攻は音響学とは一切無関係であり,この分野については素人同然なので,勉強不足な点や間違った解釈をしている点があるかもしれません.その場合はご了承ください.
基礎知識
今回の解析を理解するうえで最低限必要な知識を書いておきます.難しい数式はなるべく使わず,直感的な説明を目指してみます.(数式書くのめんどくさい)(そもそも自分自身が正確に理解できてる自信がない)
フーリエ変換
音声解析において必須になる手法といえばフーリエ変換ですね.フーリエ変換とは簡単に言うと「音声波形を周波数成分に分解すること」です.
音は空気の波です.また,全ての形の波はサイン波 (高校数学で皆が見たことがある,y=sin(x)のグラフのこと) の組み合わせでできています.周期や振幅が違うサイン波を複数重ね合わせると,好きな形の波を作ることができます.
波をフーリエ変換すると,どんな周期・振幅のサイン波がどれくらい波に含まれているかがわかります.こうして音声波形に含まれるサイン波の周波数特性を見ることで音声の特徴を分析できるというわけです.

画像引用元:https://environmental-engineering.work/archives/444
「倍音」について
倍音とは基音とは別の周波数を持った音の成分です.基音は声のベースとなる周波数で,最も低い周波数の部分を指します.
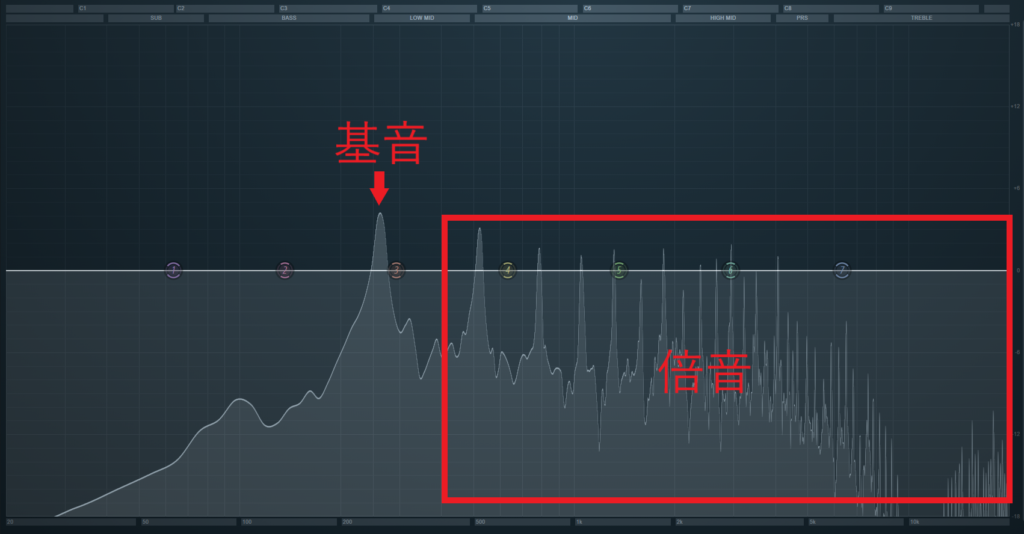
画像引用元:https://cidermusic.jp/baion/
倍音には「整数次倍音」と「非整数次倍音」の2種類があります.
整数次倍音とは,周波数が基音の整数倍の音のことです.整数次倍音が多く含まれるとクリアで艶のある声になり,例えばアナウンサーの声なんかがこれにあたります.
また,非整数次倍音とは,周波数が基音の整数倍でない音のことで,これが含まれると柔らかく親しみやすいような声になります.さらに多くの非整数次倍音があるとハスキーボイスと呼ばれるようになります.
解析手順
短時間フーリエ変換
今回は,短時間フーリエ変換(STFT)という手法を用いて短いセリフのスペクトログラムを作成していきます.
STFTでは音源を短く区切ってフーリエ変換し,次にその区切りを少し横にずらしてまたその範囲でフーリエ変換し...という手順を繰り返します.こうすることで時間ごとの音の周波数特性がわかります.
これをグラフ化すると,横軸が時間,縦軸が周波数,グラフの色がパワースペクトル強度を表した図「スペクトログラム」が出来上がります.今回はこれを使って声の特徴を分析していきます.

Pythonで音声を読み込みスペクトログラムを作る簡単なプログラムを書きました.需要があるかはわかりませんが末尾に載せておきます.ちなみに上の図の例で使った音声データは筆者(20代前半,一般男性)の声です.特に何の面白みもないですね.
PythonのScipyやnumpyなどのライブラリを使って,関数にデータを入れれば勝手にフーリエ変換してくれるので,フーリエ変換の定義式とかは知りません.
使用する音源
音源は以下のものを使用します.
まず,22/7計算中公式Twitterより,ブルーレイ第5巻カウントダウン動画
/
— 【公式】22/7 計算中&検算中 (@227keisanchu) 2022年8月29日
「22/7 #計算中 season3」Blu-ray5巻
発売まであと2⃣日💖
\
8月31日(水)発売🎉
カウントダウン動画公開📷💭
本日の担当は藤間桜役 #涼花萌 ちゃんです✨
ご予約受付中🌻
▼Blu-ray情報https://t.co/vsPVWtrUeH#ナナニジ #三四郎 pic.twitter.com/TOcIUhsKaE
この告知動画からは「22/7計算中season3」と言っている部分を使用します.また比較として,他のメンバーの声も同様の解析を行います.先輩メンバー6人分の動画があるので,全員分の解析をします.ただし,この動画は録音時に混入したノイズが大きく,妥当な解析ができるか少し怪しいということに途中で気付いたため,念のためノイズの少ない別音源も探して使用します.
というわけで次に,22/7公式サイトのARTISTページにあるサンプルボイスを使用します.
萌ちゃんのセリフ1の冒頭から「先輩!」と「試合,お疲れ様でした」を解析にかけます.また,サリーちゃんとれいにゃんのサンプルボイスに全く同じセリフがあったので,こちらも合わせて3人分の解析をし比較します.ちなみに萌ちゃんのサンプルボイスめっちゃかわいいから全人類聞いてくれ.
解析結果・考察
1. セリフ「22/7計算中season3」のスペクトログラム
解析結果を以下に示します.まずは萌ちゃんの声の解析結果から.

綺麗な倍音構造をしていますね.4000~6000Hz付近の倍音強度がとても高いこと,10000Hz以上の高周波領域まで整数次倍音が見られること,非整数次倍音が少ないことが特徴的です.
あと図に入れ忘れましたがカラーバーの単位はデシベル[dB]です.
比較のためメンバー6人のスペクトログラムを示します.

こうして見ると各メンバーの声の特徴が何となく見えてくるような気がします.例えば萌ちゃんとかなえるはノイズ少な目で整数次倍音が目立つクリアな声.れいにゃんと和ちゃんは非整数次倍音が比較的強めな,角が取れたようなフワッとした声.サリーちゃんと詩ちゃんは整数次倍音が目立ちつつも,適度にノイズが混ざったバランスのとれた声,といったところでしょうか(筆者の主観です).
何となく,耳で聞いた声から感じる印象と一致してる気がしませんか?

2. セリフ「先輩!」「試合,お疲れ様でした」のスペクトログラム
次のデータはサンプルボイスからです.


こう並べてみると,やはり特徴が周波数スペクトルに現れているように見えます.
全員に共通して言えるのは,基音(一番低い周波数のピーク)から2000Hzくらいまでは整数次倍音が綺麗に並んでいることですね.声を使う仕事をしているだけあって,この声のベースとなる部分は皆共通して美しいようです.ここから上の周波数領域にそれぞれの特徴が現れてきます.
では1人ずつ見ていきます.
まずは萌ちゃんから.

やはり10000Hz以上の高周波領域まで整数次倍音がハッキリと見えていて,ノイズも少ないことがわかります(図の赤線で囲った領域).また,他の人と比べて4000~6000Hz帯の強度がかなり強い傾向にあることがわかります(図のピンク線で囲った領域).この周波数帯こそが萌ちゃん特有のあの可愛らしく良く通る声の秘訣なのではないでしょうか.
そういえば,2022/12/27~2023/1/2の期間限定で,ローソン店内放送で萌ちゃん・かなえる・桜月ちゃんのコメントがオンエアされていたことは覚えていますでしょうか.その当時,Twitterで「涼花萌 声」「萌ちゃん 声」「ローソン ナナニジ 店内放送」などのキーワードで検索したところ,「ローソンの店内放送,萌ちゃんの声が聴きとりやすかった」「雑音でよく聞こえなかったけど萌ちゃんの声だけはしっかり聞こえた」といった感想が散見されました.この現象が生じた理由として,先に述べた通り「ノイズが少なく,高周波領域まで整数次倍音が含まれる声であり,良く通る声質である」からだと考えられます.
次はサリーちゃん

サリーちゃんも比較的高周波領域まで倍音構造が見られます.図の赤線で囲った領域は,非整数次倍音が混ざりつつも,整数次倍音のピークも埋もれていない,良い感じのバランスです.
ちなみに今回のサンプルボイスではこのような結果でしたが,声優としてキャラクターを演じているとき,また違った声質が見えてきます.

例えば上の図からわかる通り,桜ちゃんを演じているときは「整数次倍音ハッキリ,ノイズが少なく良く通る声」,キャロルを演じているときは「非整数次倍音を効かせたゆるふわボイス」.声優さんは声に乗せる倍音を使い分けることで演じ分けをする,ということですね.サリーちゃんはこの倍音の調整がかなり上手いようです.すごい.
最後にれいにゃん

3000~5000Hzあたり以降から整数次倍音のピークが埋もれ始め,非整数次倍音が効いた声になってくる傾向があります.基音~2000Hzくらいまででしっかりと倍音を響かせ,そこに高周波のノイズが乗ることであのフワッとした声が作られているんだなという印象です.こういう声はASMR向きな気がします.にゃんしよーとにバイノーラルマイクを導入したスタッフさんは有能です.
まとめ
今回はフーリエ変換を用いた解析を通じて,涼花萌ちゃんの声の魅力について考察しました.その結果,萌ちゃんの声には以下のような特徴が確認されました.
これらの特徴が,あの可愛らしく良く通る妖精ボイスが形成されている要因なのだなと考えられました.
また,比較として他メンバーの声も解析し,それぞれの特徴が周波数特性によく表れていることがわかりました.
さて,こんな自己満記事を書いてたら朝の4時になっていたので,萌ちゃんの声でも聴きながら寝ようと思います.
後日,気が向いたら音声解析第2弾もまとめてみる,かもしれません.
スペクトル解析ができるスマホアプリとかもあるので,推しの声の周波数特性に興味がある人は是非試してみてくださいね.
付録
スペクトログラムを出すpythonコード
main関数の 'soundfile.wav' のところに好きな音源ファイルを入れましょう.長すぎる音源を入れると解析にめちゃめちゃ時間がかかるうえに出てくる結果も見づらいものになってしまうので,長くても5秒程度以内の音源を使うこと推奨.
>|python|
import numpy as np
from scipy import fftpack
from scipy import signal
import librosa
def spectrogram(y,fs):
# スペクトログラム表示
N = 1024
freqs3, time3, Sx = signal.spectrogram(y, fs, window='hanning', nperseg=N, noverlap=N-100, mode='psd')
with np.errstate(divide='ignore', invalid='ignore'):
Sxx = 10 * np.log10(Sx)
plt.pcolormesh(time3, freqs3, Sxx, shading='gouraud', cmap=plt.cm.jet)
plt.ylabel('Frequency [Hz]')
plt.xlabel('Time [s]')
plt.clim(-110, -30)
plt.ylim(0,16000)
plt.show()
def main():
y1,fs1=librosa.load('soundfile.wav',sr=44100)
y1=normalize(y1)
spectrogram(y1,fs1)
if __name__=='__main__':
main()